Рассказывал про применение онтологий, OWL 2.0 и сравнение возможностей OWL с KG (Knowledge Guide, разработка ИжГТУ). Дело было в 2012 году. Составил схему лекции.
 |
| Схема лекции по OWL 2.0 (узлы с примерами свёрнуты) |
|
| Схема лекции по OWL 2.0 (узлы с примерами свёрнуты) |
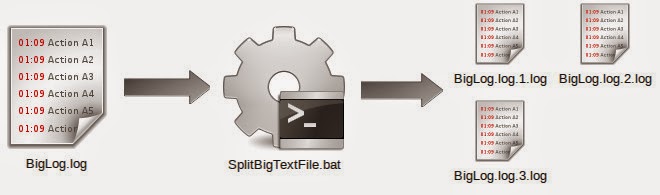
echo off
setlocal enabledelayedexpansion
set fileName=%1
set partSize=%2
set partExt=%3
set index=0
set partNumber=0
for /F "tokens=*" %%i in (!fileName!) do (
set /a index+=1
if !index! GTR !partSize! (
set /a partNumber+=1
set index=0
)
@echo %%i >> !fileName!.!partNumber!.!partExt!
)SplitBigTextFile.bat D:\BigLog.log 10000 logupdate 11 марта 2015. При работе потребуется ОЗУ в два раза больше размера файла. Для начала работы объём свободной оперативной памяти должен быть больше объёма файла. Так если файл размером 2 ГБайт, то при свободных 2,3 ГБайт процесс запустится и будет работать. Файлы более 2 ГБайт не разделял таким способом — памяти не хватает. Обработка некоторых текстовых файлов с кодировкой UCS-2 Little Endian не работает изначально (так выгружаютя файлы реестра *.reg). Чтобы заработала можно с помощью команды type перенести содержимое сбойного файла в новый файл командой:
type сбойныйФайл.txt > новыйФайл.txt
TOP(1).SELECT TOP(1) "ID", "Text"
FROM "DataTable"
ORDER BY NEWID()
SELECT TOP(1) "ID", "Text"
FROM "DataTable"
ORDER BY RAND()WHERE.SELECT TOP(1) "ID", "Text"
FROM "DataTable"
WHERE "ID" >= 100 AND "ID" <= 1000
ORDER BY RAND()RAND() и ROUND().SELECT @ID = @НачалоИнтервала + ROUND(RAND() * (@КонецИнтервала - @НачалоИнтервала), 0)SELECT @ID = 5678 + ROUND(RAND() * (105678 - 5678), 0)